Flink初体验
大数据技术
大数据基本理念
- 基本理念:分而治之。通过分布式的存储与计算方案,平摊了存储与计算的压力。
- 分布式计算方案
- 消息传递接口 MPI:多进程多节点数据通信解决方案,但是比较复杂,使用成本较高。
- 映射规约模型 MapReduce:一种简单的分布式计算编程模型,Map就是分,Reduce就是治。
大数据相关技术生态
Hadoop
| 技术 | 备注 |
|---|---|
| HDFS | 分布式存储 |
| HBase | 数据库 |
| Yarn | 资源调度 |
| Zookeeper | 协调管理 |
| Sqoop | 数据管道 |
| Hive | SQL on Hadoop |
| Spark | 内存计算 |
| Flink、Kafka | 流处理 |
Spark
- 比原生MapReduce更加友好;基于内存计算,速度更快。
| 技术 | 备注 |
|---|---|
| Spark核心 | |
| Spark SQL | |
| Spark Streaming | 流处理,基于mini-batch |
| MLLib | |
| GraphX |
Kafka
- Kafka作为消息队列一般作为不同系统之间的数据管道,其也有原生的流处理框架。
Flink
第三代流处理技术(第一代是Storm,第二代是Spark Streaming)
优点
- 支持多种时间语义,可以处理乱序到达数据
- Exactly-Once保障
- 毫秒级延迟
- 简单易用的API
- 易于拓展,生态丰富
大数据处理平台演变
传统数据处理
- OLTP,事务处理:计算与存储分离,实时性较好,能够处理的数据量有限。
分析处理
- OLAP,将数据从业务数据库中复制到数据仓库,再进行查询与分析
Lambda架构
- 为了保证实时性与准确性,同时采用批处理以及流处理对源数据进行处理(同时使用OLTP与OLAP)
- 需要开发与维护两个系统
Kappa架构
- 舍弃批处理层,批流合一
流处理基础
延迟与吞吐
延迟 Latency,表示一个时间被系统处理的总时间。分为平均延迟以及分位延迟。
吞吐 Throughout,表示一个系统最多可以处理多少时间。
延迟高,吞吐量一般就比较小。
窗口与时间
窗口
- 滚动窗口 Tumbling Window,定长,窗口之间不包含重复数据。
- 滑动窗口 Sliding Window,定长,窗口之间包含重复数据。
- 会话窗口 Session Window 不定长,使用会话间隔(Window Gap)划分事件
时间语义
- Event Time 事件实际发生的时间
- Processing Time 事件被流处理引擎处理的时间
Watermark
- 控制数据接收的最长等待时间
状态与检查点
- 计算分为有状态计算与无状态计算
- 检查点主要是保存状态数据
数据一致性保障
- At-Most-Once,可能丢数据
- At-Least-Once,可能重复处理数据
- Exactly-Once,不重不漏数据
Flink
基础概念
- Flink 是一个分布式处理引擎与框架,用于对无界和有界数据进行状态计算。
- 传统的数据架构是基于有限数据集的,而流式数据更加真实地反映了生产环境的数据产生特点。流式数据处理的目标是低延迟、高吞吐、结果的准确性、良好的容错性。
Flink特点
- 事件驱动
- 一切皆是流:离线数据是有界流,实时数据是无界流
- 分层的API结构(Table API、DataStream(DataSet) API、ProcessFunction)
安装配置
本地测试
测试环境是Kafka系列中配置的Kafka集群
- 在IDEA中编写如下测试程序
1 | import lombok.extern.slf4j.Slf4j; |
- 创建对应的topic并发送数据,
kafka-console-producer.sh --broker-list kafka1:9092 --topic flink-test-topic
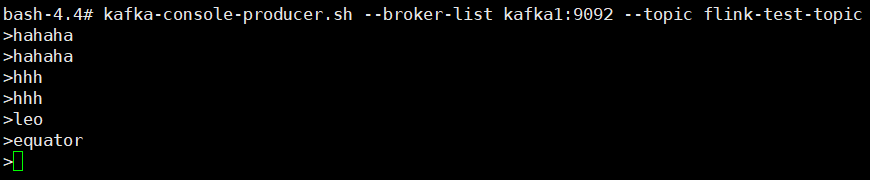
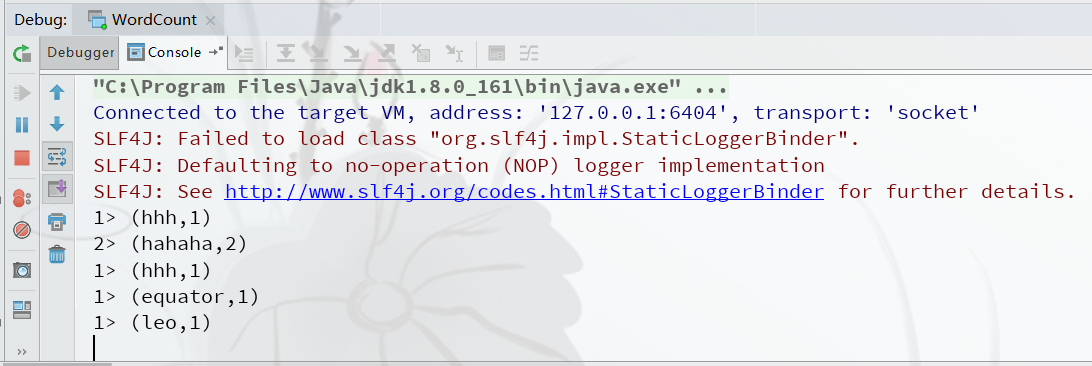
- 在控制台可以看到wordcount的输出
集群配置
- 创建自定义网络
1 | docker network create --driver=bridge --subnet=172.18.0.0/16 --gateway=172.18.0.1 my-cluster-network |
| 服务 | IP | 端口(主机:容器) |
|---|---|---|
| zookeeper1 | 172.18.1.1 | 2181:2181 |
| zookeeper2 | 172.18.1.2 | 2182:2181 |
| zookeeper3 | 172.18.1.3 | 2183:2181 |
| kafka1 | 172.18.2.1 | 9092:9092 |
| kafka2 | 172.18.2.2 | 9093:9092 |
| kafka3 | 172.18.2.3 | 9094:9092 |
| jobmanager | 172.18.3.1 | 8081:8081 |
| taskmanager1 | 172.18.3.2 | none |
- 编写配置文件
flink-cluster.yml
1 | version: '3' |
- 启动集群,
docker-compose -f flink-cluster.yml up -d
提交作业到集群
- 修改代码中Kafka相关配置
1 | conf.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka1:9092;kafka2:9092;kafka3:9092"); |
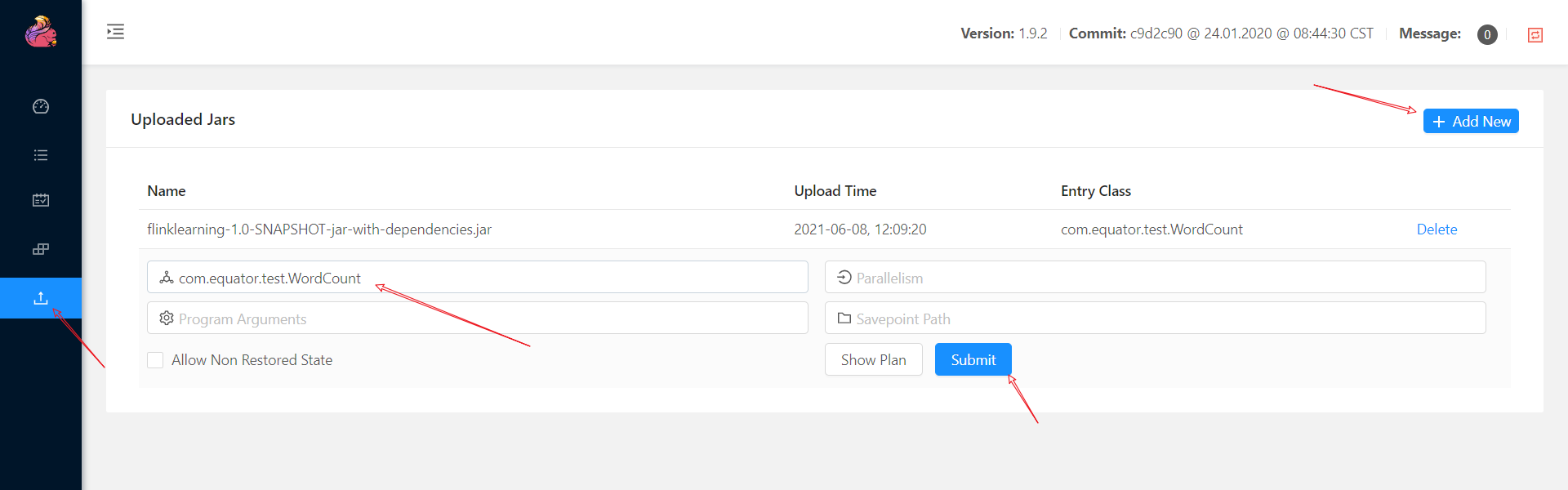
- 通过maven将程序打包为jar文件(注意需要将依赖打包到jar包中),通过Flink Web UI提交作业到集群
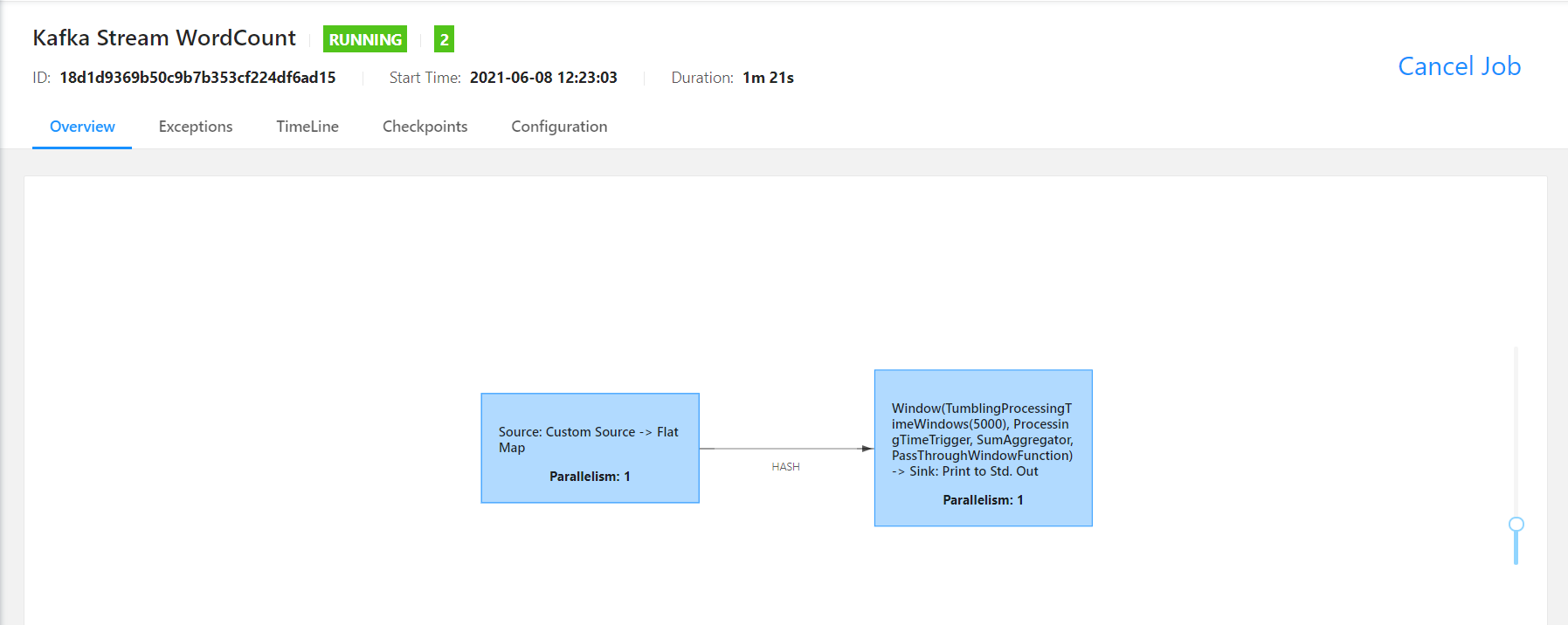
- 查看Job运行状态,正常运行中
- Kafka生产数据,通过命令
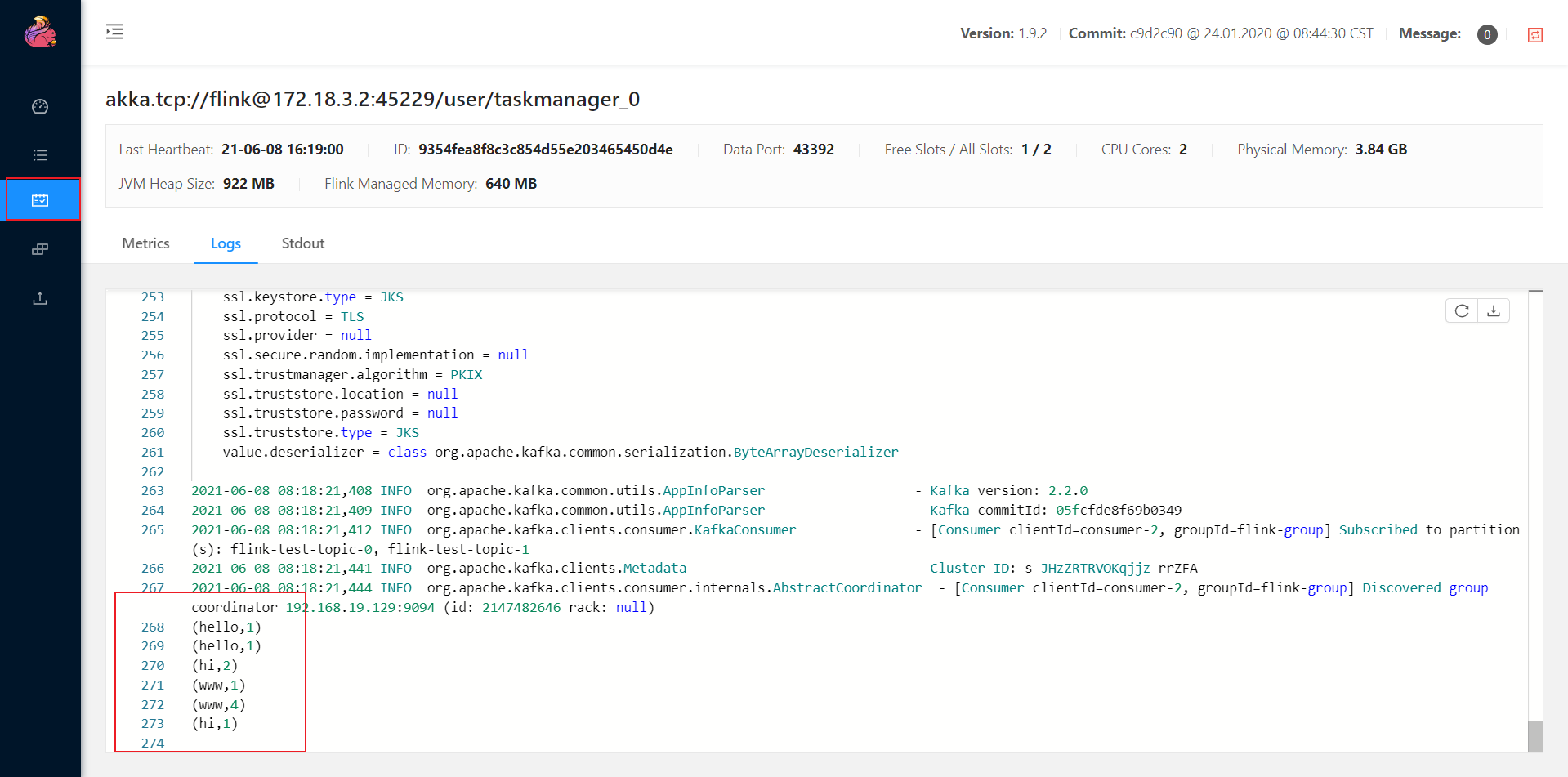
docker logs taskmanager1 -f查看Job输出

Web UI查看输出配置
- 在Web界面查看输出,发现无法查看日志
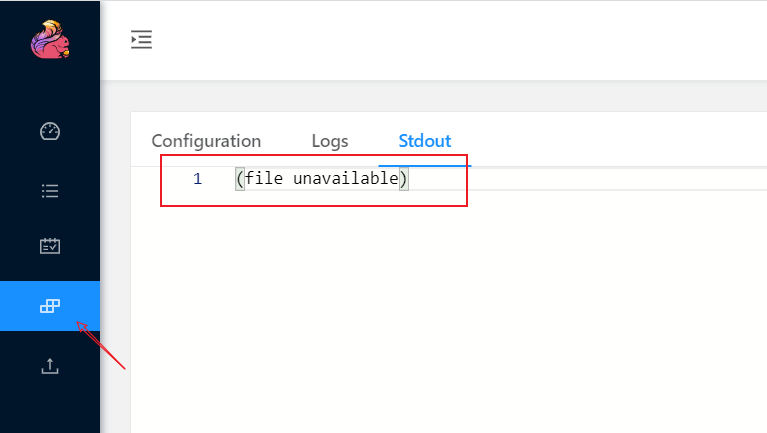
- 到
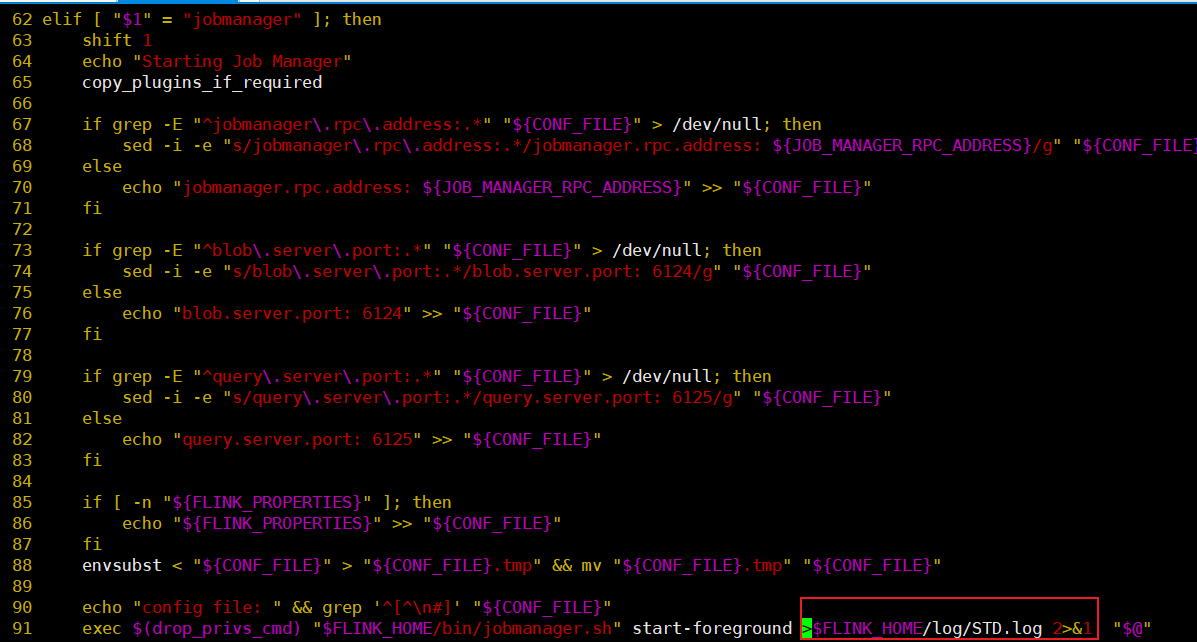
jobmanager容器根目录下修改配置文件/docker-entrypoint.sh,指定重定向文件路径>$FLINK_HOME/log/STD.log 2>&1。(安装vim命令如下apt-get update && apt-get install vim)

- 配置文件
/opt/flink/conf/flink-conf.yaml添加配置
1 | web.log.path: /opt/flink/log/STD.log |

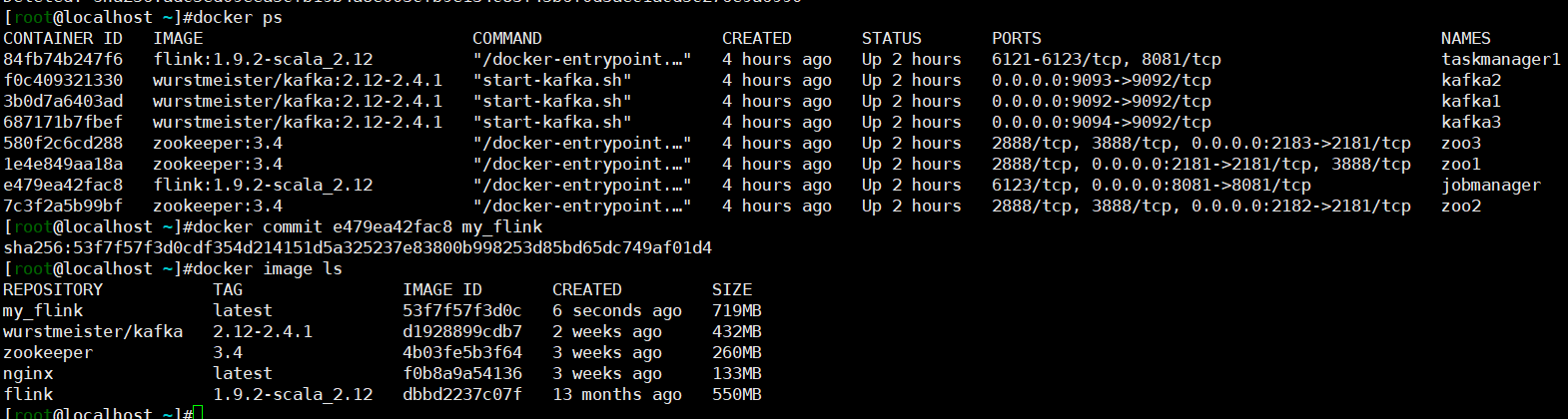
- 可以创建新的镜像以便复用
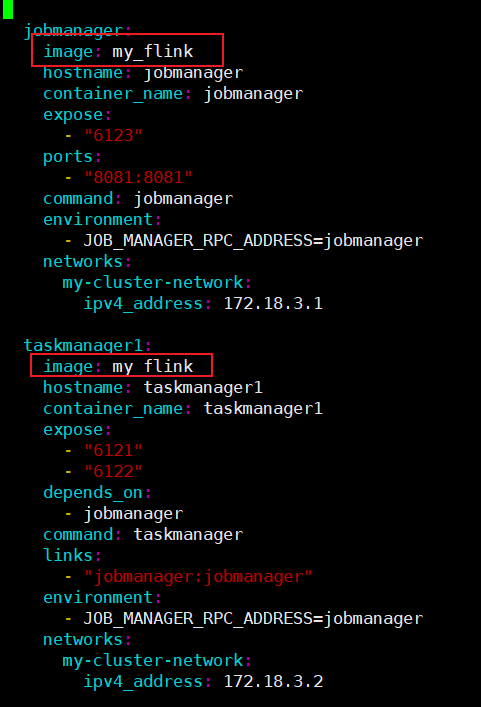
- 修改docker-compose文件
- 重启集群,重新提交任务并查看日志
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Equator's Blog!

