Kafka使用教程
命令
命令行中使用Kafka,一般用于测试
Topic
查看
- 查看主题列表,
kafka-topics.sh --list --zookeeper zoo1:2181
增加
- 创建主题,
kafka-topics.sh --create --topic mytopic --replication-factor 3 --partitions 2 --zookeeper zoo1:2181 partitions必须小于等于broker的数量,replication-factor与broker的数量没有必然的关系
删除
- 删除主题,
kafka-topics.sh --delete --topic mytopic --zookeeper zoo1:2181
查看主题元数据
- 查看主题数据,
kafka-topics.sh --describe --topic mytopic --zookeeper zoo1:2181


Producer
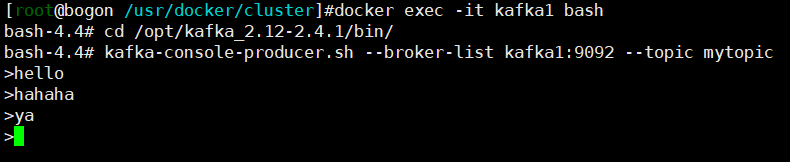
生产数据
kafka-console-producer.sh --broker-list kafka1:9092 --topic mytopic
Consumer
消费数据
kafka-console-consumer.sh –zookeeper zoo1:2181 –topic mytopic –from-beginning,已过时。0.9版本之后,Kafka消费者不使用zookeeper保存数据。kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic mytopic --from-beginning。--from-beginning,从头开始消费

API
代码中使用Kafka
Producer API
消息发送流程
- 消息提交到线程共享变量RecordAccumulator(相当于缓冲队列),Sender线程不断地从RecordAccumulator中拉取消息发送到Kafka broker。
- 消息流向:Producer->Interceptors->Serializer->Partitioner->RecordAccumulator->Sender->Topic
- 参数配置
batch.size,发送数据的批次大小linger.ms,攒batch的最长等待时间
异步发送API
1 | import lombok.extern.slf4j.Slf4j; |
同步发送API
- 设置一个分区,使用同步发送可以保证全局有序,但是意义不大
- 同步发送依赖于Future
1 | public class MySyncProducer { |
Consumer API
自动提交offset
1 |
|
手动提交offset
1 |
|
自定义存储offset
- offset同步时间太长,处理完数据后offset提交失败,会导致重复消费数据。offset同步时间太短,数据还没有处理完,offset就提交了,会丢失数据。所以需要自定义存储offset引入事务机制。
- 维护offset的维护需要考虑到消费者的rebalance场景。消费者的rebalance指的是当有新的消费者加入消费者组、已有消费者退出消费者组或者消费者组订阅的主题分区发生变化,就会触发分区的重新消费。rebalance后,消费者需要获取到自己被重新分配到的分区,并定位到每个分区最近提交的offset位置继续消费。
自定义Interceptor
拦截器原理
拦截器案例
- 修改拦截器
1 | public class TimeInterceptor implements ProducerInterceptor<String, String> { |
- 计数拦截器
1 |
|
- 指定拦截器列表
1 | // 添加拦截器 |
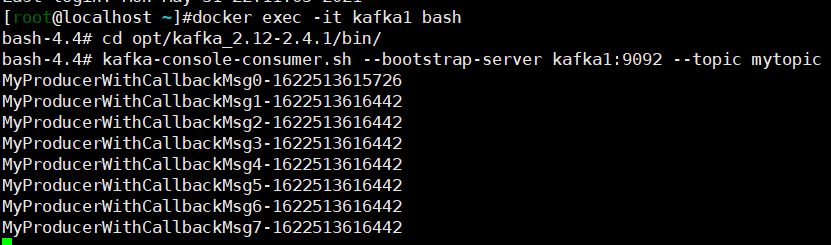
- 测试

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Equator's Blog!

